برای دسته بندی تصاویر باید یه Classifier انتخاب کنید .. MLP یا Naive Bayes یا KNN یا SVM یا AdaBoost یا .... باید ببینید کارتون به کدوم یکی از اینا مخوره .. موفق باشید ..
برای دسته بندی تصاویر باید یه Classifier انتخاب کنید .. MLP یا Naive Bayes یا KNN یا SVM یا AdaBoost یا .... باید ببینید کارتون به کدوم یکی از اینا میخوره .. موفق باشید ..
ممنون از توجه شما .من یک سری ویژگیها را از طریق روشهای میدانهای تصادفی مارکوف و گابور استخراج کرده ام حدود29 ویژگی حالا نمی دونم چطوری با استفاده از این ویژگیها تصویرم را مثلا با استفاده از یک طبقه بندی کننده بیزی طبقه بندی کنم.
Bayes Classifier استفاده از قاعده ی بیز برای دسته بندی دیتا های موجوده .. روش کارش به چه صورته؟ من خیلی خلاصه سعی میکنم روی اصولش تاکید کنم؛ هر جاش رو که احساس کردید بد گفتم تاکید کنید تا دوباره بگم ..
یه Classifier خیلی معروف که با تئوری Bayes کار میکنه؛ Naïve Bayse هست .. توی این پست در مورد این Classifier صحبت میکنیم .. صحبت کردن از این Classifier به این معنا نیست که یه خانواده ی خیلی خاص از شبکه ی های Bayesian هست؛ نــه اصلا .. بلکه این Classifier یه حالت خیلی متدوال در شبکه های Baysian هست که جلوتر میگیم چه خاصیتی داره .. این Classifier بیشتر برای مواقعی استفاده میشه که بعد ورودی های ما زیاد باشن .. در این موقع Naïve Bayes خیلی بهتر از متدهای دیگه میتونه به Classification ما کمک کنه .. (البته این حرف هیچ وقت صد در صد نیست و قاطعیتش بستگی به خیلی چیزا داره) پس؛ میریم ببینیم این Classifier چه ویژگی هایی داره؛ چه طور کار میکنه و چطور منطق بیز به کمک Classification میاد ..
برای اینکه بهتر بتونیم باهم روی این Classifier صحبت کنیم ؛ فرض کنید داده های ما به دو دسته ی کلی قرمز و سبز تقسیم بشن و در یک فضای دو بعدی بتونیم اونهارو نگاشت کنیم (یا ببینیم) .. مثال این گفته میشه تصویر زیر .. توی تصویر زیر داده های ما به دو دسته ی کلی قرمز و سبز تقسیم بندی شدن و قراره دو تا کار صورت بگیره .. یکی اینکه یه Decision Boundary بندازیم بین داده هامون که بتونیم اونهارو از هم جدا کنیم و دوم اینکه با یه تعمیم یا همون Generalization خوب بتونیم پیش بینی کنیم داده ی جدیدی که میاد؛ چیه؟ قرمزه یا سبزه .. تا اینجاش که موردی نیست؟
توی شکل بالا دقیقا میخوایم چی بگیم؟ یه سری دیتا داریم که قرمزن و یه سری دیگه هم داریم که سبزن .. الان ما میتونیم بگیم دو دسته آبجکت داریم که با لیبل قرمز و سبز از هم جدا شدن .. هدف اصلی چیه؟ اینه که بتونیم روی دیتای جدیدی که وارد میشه، قضاوت کنیم .. یعنی بگیم سبزه یا قرمزه .. این تصمیم باید از روی چی انجام بشه؟ اطلاعاتی که الان در اختیار داریم یعنی خیلی دقیقتر از اطلاعات مرحله ی Train استفاده میکنیم تا بتونیم برای Generalization مدلمون حرفی داشته باشیم .. همونطور که توی Train (یعنی مرحله ی آموزش) ما دو لیبل برای آبجکت یا همون دیتاهامون داریم (یا قرمز یا سبز)؛ انتظار داریم که توی تست هم بتونیم دیتای جدید رو با یکی از دولیبل قرمز یا سبز، پیش بینی کنیم .. پس این نکته رو به یاد داریم ..
حالا این حرفایی که در بالا زدیم رو میخوایم وارد ادبیات Bayesian Networksکنیم و ببینیم بیان ریاضی اونا چی میشه؟ اتفاقی که در مرحله ی Train میوفته اینه که یه سری اطلاعات داریم که به ما کمک میکنن تا روی داده های موجود (Ground Truth) مدل بزنیم .. این اطلاعات اولیه رو ما با احتمالات اولیه مدل میکنیم .. یعنی چی؟ یعنی یه احتمال ساده میزنیم روی دیتاهامون و برای هر لیبل احتمال اولیه اش رو به دست میاریم .. توی Bayesian Network به این اطلاعات اولیه میگن Prior Probabilities .. اطلاعات اولیه مبناشون بر تجربیات گذشته است .. یعنی اطلاعاتی که روی Ground Truth تعریف شدن .. مثلا برای شکل بالا ما میتونیم به رابطه های زیر استناد کنیم ..
اگه از فرمول بالا بخوایم برای داده هامون استفاده کنیم یه عدد برای هر کدوم از اونا به دست میاد .. مثلا برای داده های سبز عدد احتمال اولیه میشه 40 به 60 و عدد احتمال اولیه برای دیتاهای قرمز میشه 20 به 60 .. حالا اتفاقی که افتاده چیه؟ داده های ما به فرم بیز؛ تونستن بیان بشن (البته نگید که احتمال شرطی توی بیز کجا رفت و ... داده های ما مستقل هستن و میتونیم مستقیم اونها رو از فضای نمونه مون به دست بیاریم ..) .. الان آماده ی این هستیم که یک داده ی جدید بگیریم و ببینیم چیه؟ قرمزه یا سبز .. داشته های ما چیا هستن؟ احتمالا .. فقط و فقط ..
فرض کنید یه داده ی جدید میاد توی داده های ما میشینه و قراره که ما که تصمیم بگیریم این قرمزه یا سبز .. از اونجاییکه داده های ما خیلی خوب Cluster شدن (یعنی همرنگ ها پیش هم جمع شدن) میتونیم چیکار کنیم؟ Likelihood داده ی X که همون عنصر ورودی ماست رو به دست بیاریم و از روی اون بگیم که داده میتونه متعلق به کدوم لیبل باشه .. الان Likelihood برای داده ی X چطوری تعیین میشه؟ خیلی عادی فرض کنید یه دایره میکشیم دور داده ی X و نسبت هر رنگ رو به کل داده های موجود توی اون دایره به دست میاریم .. این حالت یه تعریف خیلی نمادین از مفهوم Likelihood هست که البته در عمل ما به چنین نمادی کاملا روبرو میشیم منتهی یک مقدار تعابیر فرق داره .. امــا ایده مهمه .. ایده رو بگیرید .. شکل زیر رو ببینید تا ادامه بدیم ..
توی شکل بالا اون دایره رو میبینید .. اون دایره به این معناست که توی اون ناحیه باید برای X تعریف Likelihood داشته باشیم .. توی اون دایره سه تا آبجکت قرمز وجود داره؛ یک آبجکت سبز و یک آبجکت سفید .. آبجکت سفید که همون داده ی تازه وارد یا X ماست .. قراره چه اتفاقی بیوفته؟ بگیم که به احتمال زیاد داده ی X قرمزه .. ولی چطوری؟ میایم Likelihood رو برای X به ازای دو لیبل سبز و قرمز حساب میکنیم .. شکل زیر این محاسبه رو نشون میده ..
از رابطه های بالا کاملا مشخصه که Likelihood داده ی X به ازای دیتاهای سبز کمتر از این مقدار برای دیتاهای قرمزه .. در نتیجه میتونیم همین جا بگیم که احتمالا داده ی ناشناس یک آبجکت قرمزه امــا این خاتمه ی کار نیست و نمیتونیم همین جا اعلام نتیجه ی نهایی کنیم .. یک مرحله ی دیگه از کار مونده و اون هم بر میگردذه به یه تعریف دیگه در ادبیات Belief Networks (یا همون شبکه های Bayesian) وجود داره که مربوط به prediction یا پیش بینی احتمال میشه و اون Posterior probability هست .. اگه صرفا بخوایم روی اطلاعات اولیه قضاوت کنیم باید بگیم X لیبل سبز داره چرا؟ چون تعداد سبز ها از قرمز ها بیشتره .. اما از اون طرف؛ اگه بخوایم روی اطلاعات Posterior قضاوت کنیم؛ یعنی فضای ذهنمو رو ببریم به جایی که دایتای جدید وارد شده؛ باید بگیم X لیبل قرمز داره .. تحلیل Bayesian میاد میگه این دو تا فضای استلال باید باهم ترکیب بشن تا از مجموعه ی اونا استفاده بشه تا بتونیم روی Classification نهایی قضاوت کنیم .. این اتفاق چه طور فرمولیزه میشه؟ باید بیایم اون احتمال اولیه رو که در بردارنده ی فضای اولیه ی ماست با Likelihood که در واقع بازگو کننده ی فضای جدید ماست؛ ضرب کنیم و به مفهوم ضرب اینطور نگاه کنیم که یه ترکیب و تلفیق خطی ساختیم که این دو فضا میتونن به صورت خطی روی هم اثر بذارن .. یعنی چی؟ تصویر زیر این فرمولیزیشن رو به خوبی نشون میده ..
حاصل این فرمولیزیشن چی بود؟ یه احتمال که نسبت داده میشه به X به ازای هر لیبل .. الان بر مبنای عدد احتمال Posterior میتونیم برای کلاس X قضاوت داشته باشیم .. یعنی بگیم چون ایم مقدار برای لیبل قرمز بیشتر از لیبل سبزه؛ در نتیجه داده ی X قرمزه و این هدف اصلی در Classification هست یعنی اینکه یه مدل از روی یه سری داده ی اولیه آموزش ببینه و خودش برای داده های جدیدی که نه الزاما اونها رو در Train دیده، بتونه تصمیم گیری و قضاوت داشته باشه .. همونطوری که در بالا دیدیم که همین عمل صورت گرفت .. مطالبی که در بالا با هم روش صحبت کردیم؛ بحث روی ایده ی Classification با استفاده از تئوری بیز بود .. الان ما آبجکت های Train مون رو چطور از هم جدا کردیم یا بهتر بگم چطور تفکیکشون رو بیان کردیم؟ صرفا از روی رنگ .. اینجا ما یه Feature داشتیم و اون رنگ بود .. با اون تونستیم مسالمون رو که یه مساله ی خیلی ساده و تقریبا حالت خاص بود حل کنیم .. حالا برای کارای دیگه این Feature ها باید تغییر کتنن؛ تا بتونن به Discrimination ما کمک کنن .. یه ToolBox هست که برای Bayesian classification نوشته شده .. میتونید اون رو از لینک زیر ببینید .. اگه اونو به دقت بخونید تقریبا متوجه نوع Feature های قابل پوشش اون هم میشید .. موفق باشید ..
با عرض سلام وخسته نباشید خدمت شما دوست عزیز
از این همه زحمتی که متحمل شدی ممنونم. من یه سری فایل پیدا کردم .اگه ممکنه شما هم یه نگاه کنید. مخصوصا در مورد bayesc.m ، و یا اینکه چگونه این فایلهای mat را با استفاده از ویژگیها و ابجکتها و کلاسهای مربوطه ساخته. باز هم ممنونم.( dataset ها به صورتmat تعریف شد وobject هاو features ها و classها نیز تعریف شده مثل satellite.mat,satellite.m اما نمی دونم یک فایل mat با این ساختار را چگونه باید ساخت.)
http://ifile.it/kyl1bu7/prdatasets.rar
http://ifile.it/fk1slp9/prtools_ac.zip
معمولا توی کارایی که با دیتایس انجام میدیم؛ دو تیپ روش وجود داره که میشه ازشون استفاده کرد .. یا تصاویر به صورت فایل ها گرافیکی مثل انواع فرمت های تصویری ذخیریه میشه و باید برنامه ای بنویسیم که بشه اونهارو توی متلب به کار برد .. یا اینکه این تصاویر رو با فرمت .mat ذخیره میکنن .. اینم یه راهیه که خیلی جاها استفاده میشه .. الان فکر کنم اینجا هم از روش دوم استفاده کردن .. یعنی دیتاتبیس کلاس ها رو با یه فرمت .mat ذخیره کردن .. کاری که شما میکنید باید این باشه که فایل رو در متلب لود کنید و مشخصات فایل رو با دستور whos بخونید .. اونوقت یه برنامه بنویسیسد که تصاویر رو Scale به Scale بکشه بیرون و برای مرحله ی Feature Extraction آمادش کنه .. اون یکی فایلی هم که میگید برای Feature با فرمت .m ذخیره شده میاد و Feature های مورد نیاز شمارو بهتون میده .. دقت کنید که الزاما الگوریتم ها و روش های محاسبه ی اونهارو بهتون میده و در واقع داره بهتون میگه که برای ساختن یه Vector از Feature ها نیاز به چه روش هایی دارید .. موفق باشید ..
این تاپیک غیر فعال بود اما یه سوال داشتم. می شه توضیح بدین که این برچسب های قرمز و سبز در تصویر چگونه بدست می آن و احتمال اونها در یک تصویر رو چه جوری بررسی می کنن. اگر ممکنه یک مقدار در مورد استفاده از روش بیزی در پردازش تصویر توضیح کاملتری بدین. در واقع من هنوز تو این مدل نمی دونم برچسب رو چه جوری و با چه روشی باید زد.
این تاپیک غیر فعال بود اما یه سوال داشتم. می شه توضیح بدین که این برچسب های قرمز و سبز در تصویر چگونه بدست می آن و احتمال اونها در یک تصویر رو چه جوری بررسی می کنن. اگر ممکنه یک مقدار در مورد استفاده از روش بیزی در پردازش تصویر توضیح کاملتری بدین. در واقع من هنوز تو این مدل نمی دونم برچسب رو چه جوری و با چه روشی باید زد.
منظور از اینکه گفتید تصویر رو اسکیل به scaleبیرون بکشه اینه که پیکسل به پیکسل؟؟
هرگز توان خودت را در تغيير دادن خويش،دست كم نگير!
هرگز توان خودت را در تغيير دادن ديگران،دست بالا نگير!
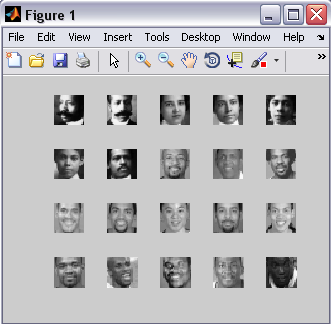
منظور از چنین اصطلاحی که در اون زمان به کار بردم؛ به احتمال زیاد این بوده که دیتاهای ذخیره شده رو ایندکس به ایندکس بخونید .. برای مثال؛ فرض کنید؛ تعدادی تصویر داریم به عنوان دیتابیس و قرار هست این تصویرها رو دانه دانه بخونیم و پردازشی که مد نظرمون هست رو بر روی اونها انجام بدیم (اعمال ویژگی یا برای مثال یک فیلتر کردن معمولی) .. یک روش این هست که همه ی تصاویر رو در یک فایل داشته باشیم و در برنامه ای که مینویسیم؛ قید کنیم که "به فایلی موجود در آدرس چنان بریم و تصویر اول رو بخونیم؛ پردازش مورد نظر رو بر روی اون انجام بدیم؛ بعد به سراغ تصویر دوم بریم؛ و بعد تصویر سوم و بعد تصویر چهارم و همین طور تا کلیه ی تصاویر" .. یک روش دیگه این هست که یک mat. فایل بسازیم از تصاویرمون؛ به گونه ای که همه ی تصاویر در اون ذخیره باشن (در صورت امکان و با توجه به محدودیت های MATLAB) یک بار در آغاز برنامه؛ این فایل دیتابیس رو load کنیم و با توجه به متغییری که در فایل ذخیره شده؛ تصاویر رو بخونیم (دانه دانه) و پردازش لازم رو بر روی اونها انجام بدیم .. با این روش؛ از نظر هزینه ی اجرای برنامه؛ بسیار زمان و بار محاسباتی (فراخوانی -- آدرس دهی -- بازخوانی --) ذخیره کردیم .. به عنوان مثال؛ فرض کنید؛ mat. فایلی داریم با نام faces.mat و میخوایم 20 تصویر ابتدای اون رو ببینیم (یک عملیات کاملا ساده -- نه فیلتری در کار هست؛ نه تبدیلی و نه حتی ویژگی ای --) .. این اتفاق به صورت زیر میتونه در MATLAB انجام بشه .. موفق و سلامت و شاد باشید ..
ببخشید میشه راهنمایی کنید چظور فایل تصاویری که داریم رو به صورت .mat سیو کنیم.
من یک فایل دارم شامل 700 تصویر به عنوان دیتابیس برای تشخیص هویت می خواهم ازش استفاده کنم.چطور آن را در متلب طبقه بندی یا خوشه بندی کنم و بخونمش.
خواهش می کنم اگه میتونید راهنماییم کنیم.












دیدگاه