

پاسخ : یک کامپایلر برای همه میکروها ، همه زبانها برای یک کامپایلر
دیگه این بحث ها داره کم کم رنگ و بوی دعوا به خودش میگیره. این یکی دیگه پست آخریه. اما بنظرم ذکر چند تا نکته خالی از لطف نیست:
opcode جاوا نوع داده ای وجود دارد به نام refrence
من باب اطلاعتون این مفهوم رفرنس بطور فیزیکی همون اشارهگر خودمونه. (حاضرم با مشاهده کد تولیدی جاوا و #C نشونتون بدم) اما از لحاظ منطقی با اشاره گر فرق میکنه. پس با این حساب شما همه زبونهای اسمبلی شی گرا هستن. که اینطوری نیست. اصلا یکی از مواردی که MSIL ایجاد شد شق شی گرا بودن زبان اسمبلی پایه نسبت به زبونهایی مثل جاوا هست.
نه اصلا منافات ندارد، مثل این می مونه بگید چون شترمرغ نمی تواند پرواز کند پس کل پرندگان نمی تواند پرواز کنند
اتفاقا من منظورم اینه که چون شما قید میکنین "همه میکروها" توصیفتون از این طرح ایراد داره. نه خود طرح و این با طرز تلقی شما از حرف من منافات داره. شما میگین که همه پرنده ها میپرن؛ و من هم نتیجه گیری میکنم که پس شتر مرغ هم باید بپره. که همه میدونن اینجوری نیست.
چون یک دستور سرعت زیادی برای پیاده سازی در این میکرو می خواهد پس کل دستورات سرعت زیادی برای اجرا در میکرو می خواهد
اتفاقا حرف من سر همینه! من اصلا کاری به "کل میکروها" و "همه امکانات بطور مشترک" برای میکرو ها ندارم. مسئله مهم اینجاست که کم کم به این نتیجه دارین میرسین که این طرح اونجوری که خودتون قید کرده بودین "در این طرح قرار این کامپایلر نوشته شود که در آن بتوان تمام میکروهای موجود را ساپورت کنه و از تمام زبانها نیز پشتیبانی کند" اصلا طبق یک اصل و نظر ثابت امکانپذیر نیست چون امکانات میکروها و نیاز هایی که ما را به سمت یک میکرو سوق میدهند و کلا موارد استفاده این میکروها شدیدا با هم متفاوته. از 4 بیتی بودن تا 32 بیتی بودن گرفته تا امکانات سخت افزاری و گرید سرعتی و غیره. بنا براین مواردی از نوع سخت افزار و آدرس حافظه و موارد فیزیکی دیگه فقط راه رو مشکل و خاص میکنه که با طرح اولیه شما منافات داره. از طرف دیگه اگه بخوایین این موارد رو هم از این طرحتون حذف کنین که چه مزیتی نسبت به یک زبون مثل جاوا یا MSIL با یک cross JIT compiler هست؟ چه چیز جدیدی قراره وسط بیاد. اینو تاکید میکنم که من جاوا رو در این مدارک نه اون زبان سطح بالایی که میتونین کلاس و شی تعریف کنین حساب میکنم. بلکه منظور من همون زبون سطح پایینی هست که pcode خونده میشه و کامپایلر های جاوا سورس جاوا رو به اون تبدیل میکنن. من میتونم تمام این کارهایی که شما میگین رو با همون جاوا یا زبونهای دیگه موجود و غیر موجود انجام بدم. ضمنا جاوا این حسن رو هم داره که خیلی از میکروهای داخل بازار بطور سخت افزاری از این زبون پشتیبانی میکنن. مثلا اینو ببینین:
http://en.wikipedia.org/wiki/ARM_architecture
و در متن برای Jazelle جستجو کنین:
Jazelle is a technique that allows Java Bytecode to be executed directly in the ARM architecture as a third execution state (and instruction set)
یعنی که این طرح قبلا ایجاد شده. یا لااقل عمده اش. شما فقط کافیه یک مجموعه نرم افزار آماده کنین که شامل یک Framework یک cross JIT compiler که کد نهایی رو از روی کد اولیه تولید کنه. و یک سری آت و آشغالهای دیگه برای استفاده راحتتر از این محیط برای کاربر ایجاد کنین. نه یک زبون اسمبلی پایه.
اینجوری بگم. من با اسمبلی و ساختار داخلی خیلی ماشین ها آشنایی دارم. اسپکتروم - آمیگا - 68000 - Z80 - 80386 - AVR - ARM - ZE02 و غیره. حتی مدتی روی ساخت یک PLC مدل S5 زیمنس کار کردم و کلی راجع بهش اطلاعات دارم. نهایتا: طرح جنابعالی چیز قشنگیه. میتونین بقول یکی از دوستان 4 موتوره هم جلو برین. اما نهایتا حیف از این همه سعی و تلاش چون میبینین که ابزار های موجود اغلب دیدهای شما رو پیاده سازی کردن و همه هم دارن استفاده میکنن و متاسفانه شما این وسط وقتتون رو تلف کردین. میدونم این لفظ یک کمی تنده ولی بهتر از این نمیتونم منظورم رو بیان کنم.....
بگذریم....
از اینکه احیانا باعث رنجش شما ممکنه شده باشم معذرت میخوام. ولی اینو بدونین که این چیزایی رو که براتون قید کردم به هیچ عنوان برای مایوس کردنتون نیست. من خودم به این اعتقاد دارم که خیلی از چیز های جدیدی که داریم و بشر اختراع یا ابداع کرد مبتنی بر نظراتی بوده که حتی در وهله اول دیوانگی محض بنظر میومده. و ضمنا هر سعی و تلاشی برای ایجاد پیشبردی در هر کاری قابل تحسینه. جلو برین. اما با چشم باز و گوش شنوا نسبت به چیزایی که بدردتون میخوره. با چشم بسته و گوش نا شنوا نسبت به افراد و چیزایی که قراره تاثیری ولو اندک در مسیر مایوس کردنتون (و نه روشنایی بیشتر) داشته باشن.
دیگه بریدم!
خدا حافظ.
(ولی خودمونیم ها! چه توی این بحث پا کار بودین!!)
دیگه این بحث ها داره کم کم رنگ و بوی دعوا به خودش میگیره. این یکی دیگه پست آخریه. اما بنظرم ذکر چند تا نکته خالی از لطف نیست:
opcode جاوا نوع داده ای وجود دارد به نام refrence
من باب اطلاعتون این مفهوم رفرنس بطور فیزیکی همون اشارهگر خودمونه. (حاضرم با مشاهده کد تولیدی جاوا و #C نشونتون بدم) اما از لحاظ منطقی با اشاره گر فرق میکنه. پس با این حساب شما همه زبونهای اسمبلی شی گرا هستن. که اینطوری نیست. اصلا یکی از مواردی که MSIL ایجاد شد شق شی گرا بودن زبان اسمبلی پایه نسبت به زبونهایی مثل جاوا هست.
نه اصلا منافات ندارد، مثل این می مونه بگید چون شترمرغ نمی تواند پرواز کند پس کل پرندگان نمی تواند پرواز کنند
اتفاقا من منظورم اینه که چون شما قید میکنین "همه میکروها" توصیفتون از این طرح ایراد داره. نه خود طرح و این با طرز تلقی شما از حرف من منافات داره. شما میگین که همه پرنده ها میپرن؛ و من هم نتیجه گیری میکنم که پس شتر مرغ هم باید بپره. که همه میدونن اینجوری نیست.
چون یک دستور سرعت زیادی برای پیاده سازی در این میکرو می خواهد پس کل دستورات سرعت زیادی برای اجرا در میکرو می خواهد
اتفاقا حرف من سر همینه! من اصلا کاری به "کل میکروها" و "همه امکانات بطور مشترک" برای میکرو ها ندارم. مسئله مهم اینجاست که کم کم به این نتیجه دارین میرسین که این طرح اونجوری که خودتون قید کرده بودین "در این طرح قرار این کامپایلر نوشته شود که در آن بتوان تمام میکروهای موجود را ساپورت کنه و از تمام زبانها نیز پشتیبانی کند" اصلا طبق یک اصل و نظر ثابت امکانپذیر نیست چون امکانات میکروها و نیاز هایی که ما را به سمت یک میکرو سوق میدهند و کلا موارد استفاده این میکروها شدیدا با هم متفاوته. از 4 بیتی بودن تا 32 بیتی بودن گرفته تا امکانات سخت افزاری و گرید سرعتی و غیره. بنا براین مواردی از نوع سخت افزار و آدرس حافظه و موارد فیزیکی دیگه فقط راه رو مشکل و خاص میکنه که با طرح اولیه شما منافات داره. از طرف دیگه اگه بخوایین این موارد رو هم از این طرحتون حذف کنین که چه مزیتی نسبت به یک زبون مثل جاوا یا MSIL با یک cross JIT compiler هست؟ چه چیز جدیدی قراره وسط بیاد. اینو تاکید میکنم که من جاوا رو در این مدارک نه اون زبان سطح بالایی که میتونین کلاس و شی تعریف کنین حساب میکنم. بلکه منظور من همون زبون سطح پایینی هست که pcode خونده میشه و کامپایلر های جاوا سورس جاوا رو به اون تبدیل میکنن. من میتونم تمام این کارهایی که شما میگین رو با همون جاوا یا زبونهای دیگه موجود و غیر موجود انجام بدم. ضمنا جاوا این حسن رو هم داره که خیلی از میکروهای داخل بازار بطور سخت افزاری از این زبون پشتیبانی میکنن. مثلا اینو ببینین:
http://en.wikipedia.org/wiki/ARM_architecture
و در متن برای Jazelle جستجو کنین:
Jazelle is a technique that allows Java Bytecode to be executed directly in the ARM architecture as a third execution state (and instruction set)
یعنی که این طرح قبلا ایجاد شده. یا لااقل عمده اش. شما فقط کافیه یک مجموعه نرم افزار آماده کنین که شامل یک Framework یک cross JIT compiler که کد نهایی رو از روی کد اولیه تولید کنه. و یک سری آت و آشغالهای دیگه برای استفاده راحتتر از این محیط برای کاربر ایجاد کنین. نه یک زبون اسمبلی پایه.
اینجوری بگم. من با اسمبلی و ساختار داخلی خیلی ماشین ها آشنایی دارم. اسپکتروم - آمیگا - 68000 - Z80 - 80386 - AVR - ARM - ZE02 و غیره. حتی مدتی روی ساخت یک PLC مدل S5 زیمنس کار کردم و کلی راجع بهش اطلاعات دارم. نهایتا: طرح جنابعالی چیز قشنگیه. میتونین بقول یکی از دوستان 4 موتوره هم جلو برین. اما نهایتا حیف از این همه سعی و تلاش چون میبینین که ابزار های موجود اغلب دیدهای شما رو پیاده سازی کردن و همه هم دارن استفاده میکنن و متاسفانه شما این وسط وقتتون رو تلف کردین. میدونم این لفظ یک کمی تنده ولی بهتر از این نمیتونم منظورم رو بیان کنم.....
بگذریم....
از اینکه احیانا باعث رنجش شما ممکنه شده باشم معذرت میخوام. ولی اینو بدونین که این چیزایی رو که براتون قید کردم به هیچ عنوان برای مایوس کردنتون نیست. من خودم به این اعتقاد دارم که خیلی از چیز های جدیدی که داریم و بشر اختراع یا ابداع کرد مبتنی بر نظراتی بوده که حتی در وهله اول دیوانگی محض بنظر میومده. و ضمنا هر سعی و تلاشی برای ایجاد پیشبردی در هر کاری قابل تحسینه. جلو برین. اما با چشم باز و گوش شنوا نسبت به چیزایی که بدردتون میخوره. با چشم بسته و گوش نا شنوا نسبت به افراد و چیزایی که قراره تاثیری ولو اندک در مسیر مایوس کردنتون (و نه روشنایی بیشتر) داشته باشن.
دیگه بریدم!
خدا حافظ.
(ولی خودمونیم ها! چه توی این بحث پا کار بودین!!)


 . طرح الان من از چیزی که در تاپیکهای اولیه نوشتم کمی متفاوت است و کمی پخته تر شده است (از برکات وجود شما) اما عنوانی که از اول مطرح کرده بودم به نظرم هنوز می تواند اجرایی شود یعنی "در این طرح قرار این کامپایلر نوشته شود که در آن بتوان تمام میکروهای موجود را ساپورت کنه و از تمام زبانها نیز پشتیبانی کند" (پخته تر شده و این اضافه شده: هر میکرویی با توجه به امکاناتش می تونه از این کامپایلر استفاده کنه)"
. طرح الان من از چیزی که در تاپیکهای اولیه نوشتم کمی متفاوت است و کمی پخته تر شده است (از برکات وجود شما) اما عنوانی که از اول مطرح کرده بودم به نظرم هنوز می تواند اجرایی شود یعنی "در این طرح قرار این کامپایلر نوشته شود که در آن بتوان تمام میکروهای موجود را ساپورت کنه و از تمام زبانها نیز پشتیبانی کند" (پخته تر شده و این اضافه شده: هر میکرویی با توجه به امکاناتش می تونه از این کامپایلر استفاده کنه)" و تا در عمل اون رو لمس نکنم و درگیرش نشم درکش نمی کنم یا من چیزی رو بیان کردم که که باعث شده شما برداشت اشتباهی بکنید و اینطور روی مسئله خاص پافشاری کنید. برای همین اگه به من یه مدتی فرصت بدهید از تاپیک بعدی می خوام دیگه وارد کار عملی بشم. یعنی برم سراغ برنامه نویسی تو کامپیوتر. من از زبان vb.net استفاده خواهم کرد.
و تا در عمل اون رو لمس نکنم و درگیرش نشم درکش نمی کنم یا من چیزی رو بیان کردم که که باعث شده شما برداشت اشتباهی بکنید و اینطور روی مسئله خاص پافشاری کنید. برای همین اگه به من یه مدتی فرصت بدهید از تاپیک بعدی می خوام دیگه وارد کار عملی بشم. یعنی برم سراغ برنامه نویسی تو کامپیوتر. من از زبان vb.net استفاده خواهم کرد.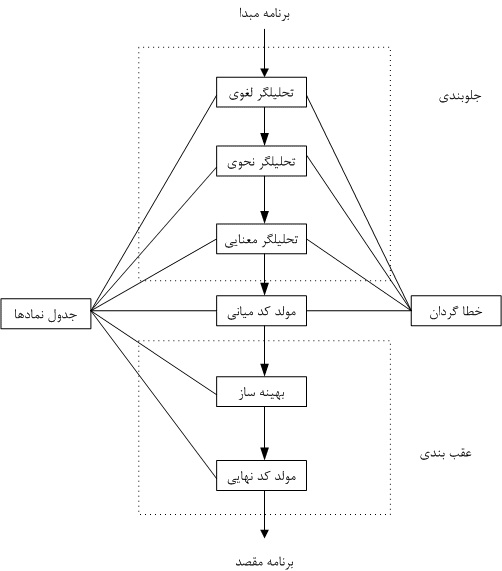
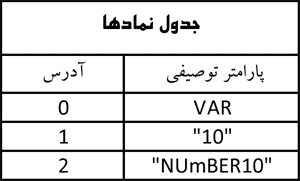

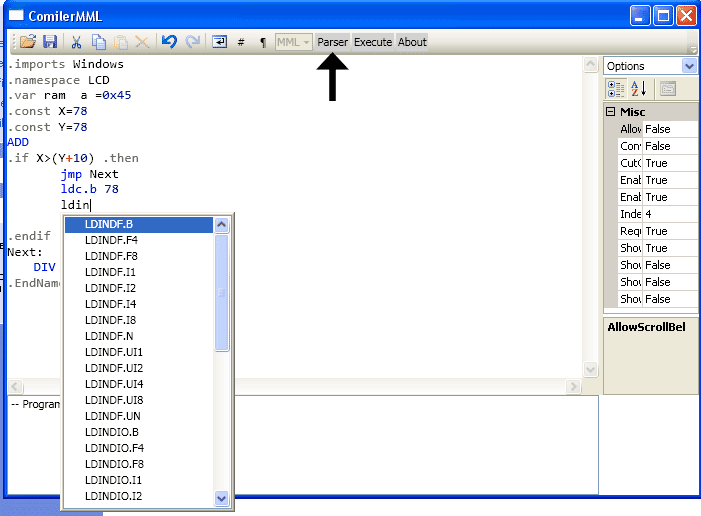


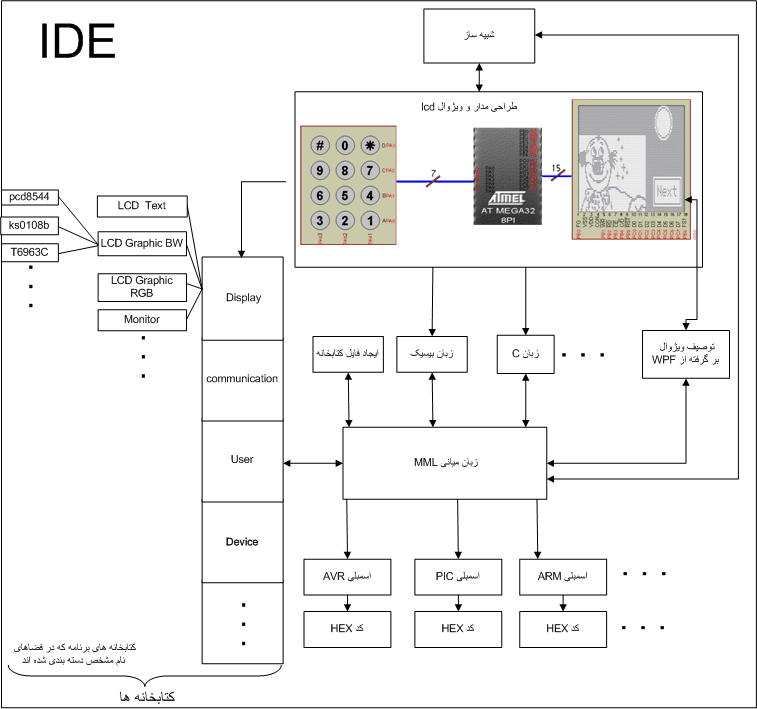
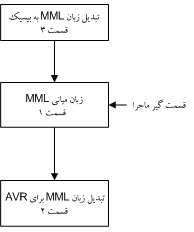


 )
)
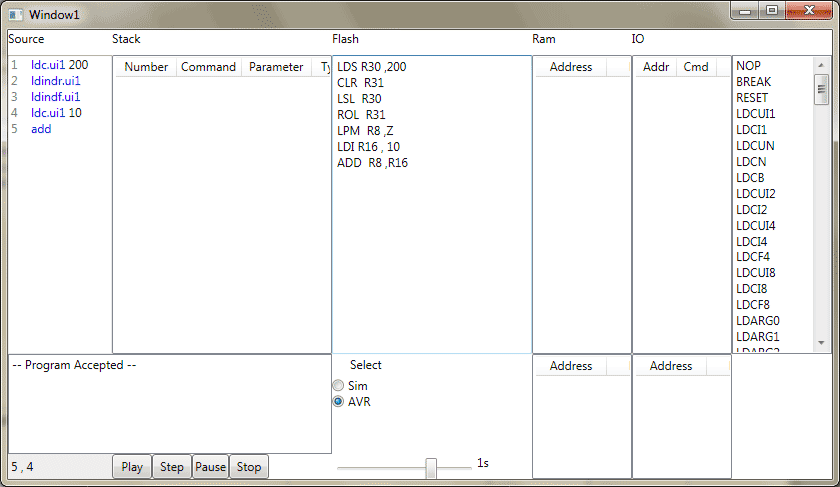



دیدگاه